Note: This article is available in Japanese also.
Amazon MemoryDB for Redis is a distributed managed database compatible with Redis interface, announced by AWS in 2021. So far, AWS has been providing Amazon Elasticache as their managed Redis. However in Amazon MemoryDB, the data consistency/durability in distributed environment is achieved as a feature. In this article, I’ll talk about the current view of Redis’s consistency/durability and how Amazon MemoryDB approaches to guarantee them. I’ll explain them based on currently opened information around the MemoryDB and I’ll leave all of them at the bottom of this article.
In this article, I’ll talk about “master-replica” model in replication, but I’ll call them “primary” “replica”.
OK then, let’s start with a generic Redis cluster, not Amazon MemoryDB.
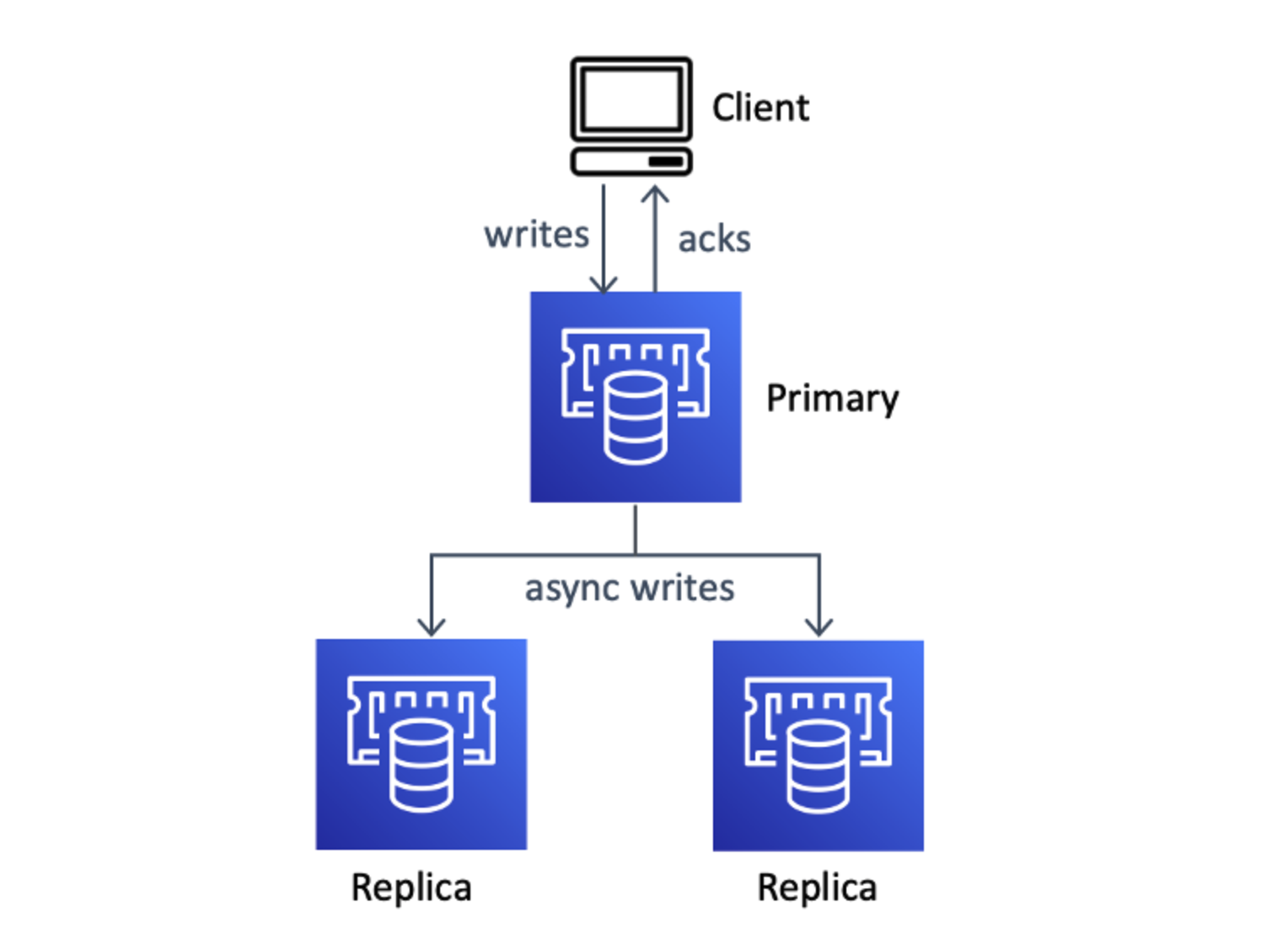
First of all, Redis cluster never guarantees the strong consistency。. In Redis, the replicated data will be eventually consistent. It means that when primary node accepts the WRITE request, writes that in data on memory, return response to the client, then propagates the change to the replicas asynchronously. This also means that if an outage occurs between the WRITE to the primary and replication and failover is triggered, then the WRITE to the primary will be lost. This is by design of Redis; Redis is designed to get better performance rather than strong consistency.
From Amazon MemoryDB for Redis – Where speed meets consistency
In Redis, it natively supports some durability mechanisms such as RDB or AOF, but none of them guarantees the strong consistency. RDB is just a periodical snapshot. So, writes between the latest snapshot and current time are not persisted.
AOF, Append Only File, is a transaction log in Redis. If AOF is enabled, while writes are committed to the data on memory in Redis, they are also written in the log file. The important thing is that they are done synchronously. On node failure, the data on memory gets lost. However, because the log file is persisted on filesystem, it won’t be lost (unless disk gets crashed). We can re-apply every line in the AOF from head to bottom to the rebooted Redis to recover all the data before the outage without any loss.

From Amazon MemoryDB for Redis – Where speed meets consistency
There are some downsides on AOF. If a dataset in Redis is big enough, re-applying every line takes much time (Usually Redis is used in very write-heavy situation). Also, there must be some performance overhead to append a line to the AOF on write (it still doesn’t need to random-access to the disk though).
AOF does not work well if it is used with clustering. Redis cluster works as primary-replica model, on failover, the replica is promoted to the primary. However, as described above, some writes might not be propageted to the replica on failover and they might be lost. If we don’t want to avoid data loss, then we can recover them from AOF instead of enabling clustering, but availability might be obstructed if the AOF re-apply (= Redis reboot) takes much time.
In Redis, despite of enabling clustering of AOF, both high availability and strong consistency/durability cannot beguaranteed. Clustering gives you the availability, but you also accept some data lost. AOF guarantees the data durability, but it might affect to its availability.
Historically, these drawbacks of Redis have been accepted because Redis is usually used just as cache store. Redis just contains the cache of data, and the real data usually can be recovered from the original datastore.
Next then, let’s talk about how Amazon MemoryDB gives us availability and consistency/durability.

From Getting Started with Amazon MemoryDB for Redis - AWS Online Tech Talks - YouTube
In Amazon MemoryDB when a primary commits the WRITE to the data on memory, it also writes to “Multi-AZ Transaction Log” synchronously. What is Multi-AZ Transaction Log? It is not described well in official documentation, but I guess it is a log in a server which locates another network with primary node. Because it is multi-AZ replicated and written synchronously, the data on memory and the content of Multi-AZ Transaction Log are consistent, while it can guarantee the strong durability.
The writes to the replica are, as well as the normal Redis cluster, done asynchronously. Internally, it looks like they are triggered by write to the Multi-AZ Transaction Log.


From Getting Started with Amazon MemoryDB for Redis - AWS Online Tech Talks - YouTube
On failover, replica is promoted to the primary. However in failover process, the promoted replica applies write operations which are not already applied to itself. The detailed process is not described, but we can come up with below simple algorithm:
uint64)In AOF, we needed to re-apply every line in the file from head to bottom to reproduce the complete data. In above approach, only non-replicated operations can be the target of re-apply, so it must require less time to recover the data. Because of this, Amazon MemoryDB can guarantee high availability AND consistency/durability.
By the way, this kind of technology is not particularly new. For example, In MySQL cluster failover, almost the same thing happens; because MySQL replication is done asynchronously using Binlog, there might be some differences between the primary (“source” in MySQL world) and the replica. Relational Databases are usually more serious about consistency than cache stores. In case of failover, it is necessary to copy the difference data to the replica. This is done automatically by MHA or mysqlfailover. (orchestrator is probably the same?) This is exactly what Amazon MemoryDB achieves.
Because AOF is persisted locally on the node, the probability of write failures must be quite low as it does not require the remote communication. Multi-AZ Transaction Log should have a relatively high probability of write failures even though it is held on the AWS network, but it will be solved by retry. I have read Amazon MemoryDB for Redis - Where speed meets consistency and learned about the MemoryDB architecture. I at first thought “This is the same as what MySQL failover automation does?”. Also, I feel this kind of work, such as “using” the existing mechanisms to make something more useful, without any innovative inspirations, is really cool. Although MemoryDB seems to cost more than Elasticache, but I think it would be a good idea to use MemoryDB when using Redis on AWS rather than Elasticache.