Note: This article is available in English also.
Amazon MemoryDB for Redisは2021年にAWSが発表したRedis互換の分散型マネージドデータベースである。 これまでAWSはマネージドRedisとしてAmazon Elasticacheを提供していたが、Amazon MemoryDBはElasticacheにはない分散環境におけるデータの一貫性・耐久性を機能として提供している。 この記事ではRedisの持つ一貫性・耐久性の仕組みを概観しながら、Amazon MemoryDBがどのように分散環境での耐久性保証を実現しているかについて、現状提供されている情報を基にまとめていく (参考とした情報は本記事末尾で列挙する) 。
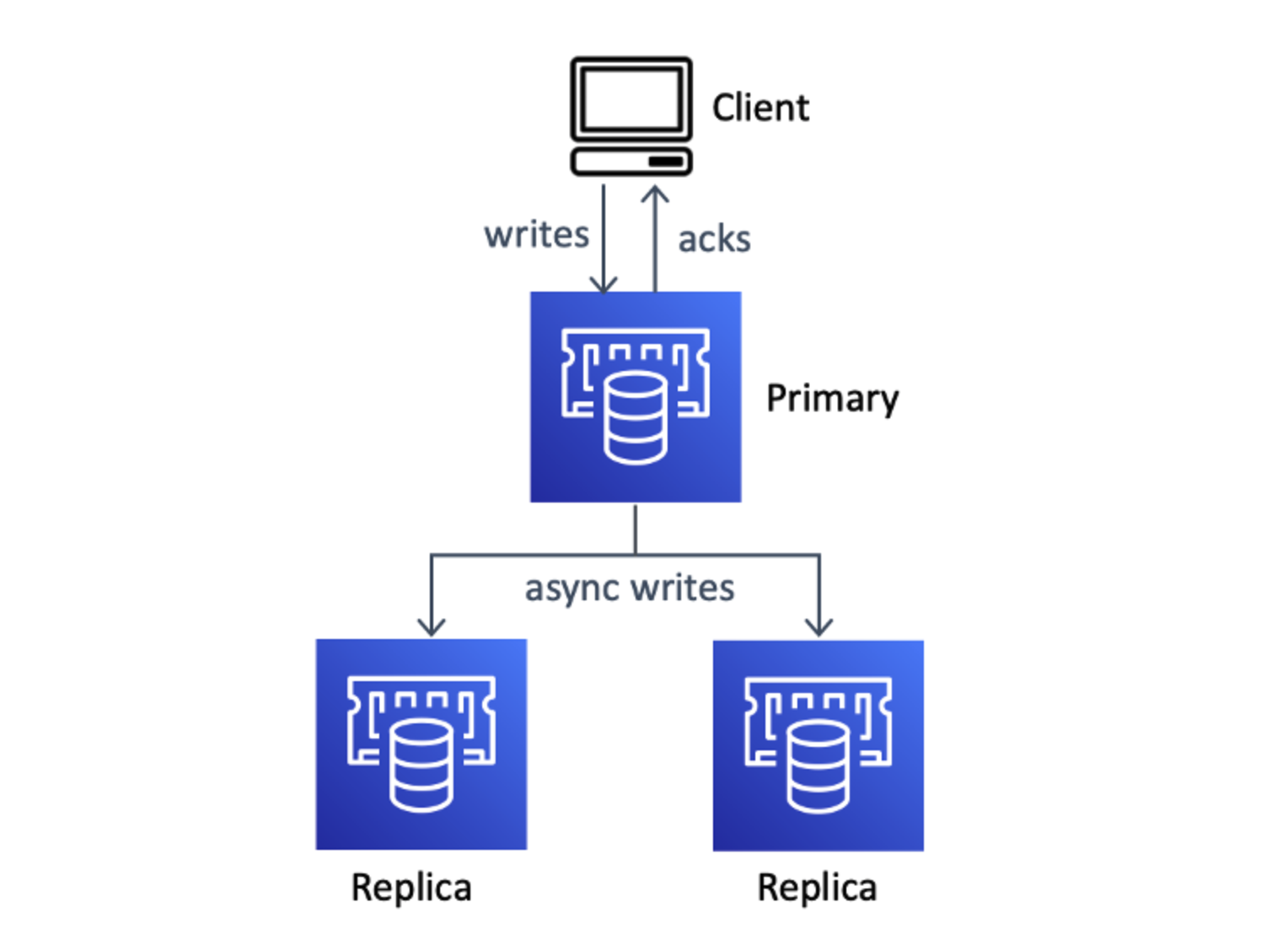
この記事ではレプリケーションにおける「マスター・レプリカ」モデルを扱うが、一貫してそれぞれを「プライマリ」「レプリカ」と呼称する。
まず、Amazon MemoryDBではなく普通のRedisクラスタの話から。
Redisクラスタは強い一貫性を保証しない。 Redisのレプリケーションは結果整合性で行われる。 すなわち、プライマリが書き込みを受け付けると、まずはクライアントにレスポンスが返り、その後非同期でレプリカに変更が反映される。 従って、プライマリへの書き込みとレプリケーションの間にプライマリに障害が発生しフェイルオーバーした場合、プライマリへの書き込みはロストする。 これによって、Redisは素早くレスポンスすることができるが、その分障害が発生した際に強い一貫性は保証できなくなる。
Amazon MemoryDB for Redis – Where speed meets consistencyより引用
RedisにはネイティブにRDBやAOFといった永続化の仕組みが備わっているが、そのどれもが強い一貫性を保証するものではない。 RDBは単なる定期的なスナップショット取得であるため、最後のスナップショット取得から現在時刻までの書き込みは常に永続化されていない。
AOFとは、「Append Only File」のイニシャリズムで、これはいわゆるトランザクションログである。 すなわち、書き込みは全てオンメモリのデータにコミットされつつ、その操作自体がログファイルに記録される。 重要なのは、データのコミットとログの記録は同期で行われることである。 ノードに障害が発生した時は当然メモリ上のデータはロストするが、ログファイルはファイルシステムに永続化されているので (ディスクがクラッシュしない限りは) 消えることはない。 すなわち、Redisのプロセスを再起動し、AOFの中身を先頭から末尾まで順に再適用していけば、データロストなく障害の直前までのデータが復旧可能である。

Amazon MemoryDB for Redis – Where speed meets consistencyより引用
このやり方にもデメリットがある。Redisが保持するデータセットが極めて大きい場合、そもそもAOFに記録された操作を全て再適用すること自体に時間がかかる。 また、単純に書き込み時に、AOFに追記する分のパフォーマンス上のオーバーヘッドが (ディスクへのランダムアクセスは発生しないにせよ) 避けられない。
AOFは、クラスタリングとの相性が良くない。Redisクラスタはプライマリ・レプリカモデルであり、フェイルオーバーの際はレプリカがプライマリに昇格する。 しかし前述の通り、フェイルオーバー時はいくつかの書き込みがレプリカに反映されておらずデータがロストするかもしれない。 データのロストを避けたければクラスタリングを辞めて障害時にAOFから復旧するようにすればよいが、これではAOFの再適用に時間がかかった場合可用性を阻害する。
Redisでは、 (クラスタリングを行うかどうかに関わらず) 高い可用性とデータの一貫性、耐久性を同時に保証することができない。 クラスタリングは可用性をもたらすが、一部のデータのロストを許容しなければならない。 AOFはデータの耐久性を保証するが、場合によってはRedisの可用性を落とす。 しかし、あくまでキャッシュストアであるというRedisの特性上、こういった欠点は歴史的に許容されてきた。 Redisはあくまでデータのキャッシュを持つだけであり、本来のデータは (データの元となるデータベースなどから) 復旧が可能なためである。
さて、ここまで読むと、AOFをレプリカからアクセス可能にすれば色々解決するじゃん?ということに気づくだろう。 Amazon MemoryDBが実現したのはまさにこれである。

Getting Started with Amazon MemoryDB for Redis - AWS Online Tech Talks - YouTubeより引用
Amazon MemoryDBは、プライマリが書き込みをオンメモリにコミットするのと同期で、「Multi-AZ Transaction Log」を書き込んでいる。 Multi-AZ Transaction Logとは、詳細は明かされていないが、おそらくプライマリとはネットワーク的に分離したサーバに存在するログであると思われる。 これはマルチAZでかつ同期で書き込みされるため、高い耐久性を実現しながらオンメモリデータとMulti-AZ Transaction Logの間の一貫性は保証される。
レプリカへの書き込みは通常のRedisクラスタと同様に非同期で行われる。実際は、Multi-AZ Transaction Logへの書き込みが伝播するようである。


どちらもGetting Started with Amazon MemoryDB for Redis - AWS Online Tech Talks - YouTubeより引用
フェイルオーバーの際は、レプリカがプライマリに昇格する。しかし、フェイルオーバープロセスの中で、プライマリに昇格するレプリカはMulti-AZ Transaction Logのうち自身に適用されていないオペレーションだけを適用する。 ここの詳細は公開されていないが、例えば以下のようなアルゴリズムが考えられる。
uint64 )AOFではファイルの先頭から末尾までを全て再適用しないと完全なデータが再現できなかった。上記のアプローチでは、適用されていないオペレーションのみを適用可能なため、データの復旧にかかる時間が大きく削減できると思われる。これによって、Amazon MemoryDBは高い可用性と一貫性・耐久性を同時に実現できる。
さて、こういった技術は特に新規性のあるものではない。 例えば、MySQLクラスタをフェイルオーバーするとき、MySQLのレプリケーションのBinlogを使って非同期で行われるので、結局はソースとレプリカでの差分が発生する。 RDBは通常、キャッシュストアよりも一貫性にはシビアである。フェイルオーバーの際は結局はレプリカへの差分データのコピーを行う必要があり、これを自動で行うのがMHAやmysqlfailoverである。 (orchestratorもおそらく同じ?) これはまさしくAmazon MemoryDBが実現していることである。
AOFはノードローカルに保有するので、ネットワーク通信が不要な分書き込みの失敗の確率がかなり低い。Multi-AZ Transaction LogはAWS内のネットワークとはいえ書き込み失敗の確率が比較的高いはずだが、リトライなどで解決可能だと思われる。 筆者はAmazon MemoryDB for Redis – Where speed meets consistencyを読んでいてMemoryDBのアーキテクチャを知った。一通り読んで、「これMySQLクラスタのフェイルオーバー自動化ツールがやってるやつじゃん」と思うと同時に、こういった既に世の中にある仕組みを流用して何かを少し便利にするようなエンジニアリングはクールだな、と感じこの記事を書いた。Amazon MemoryDBはElasticacheよりもコストがかかりそうだが、今後は基本的にAWSでRedis使う場合はMemoryDBを採用するのが良いではないだろうか。